The Hidden Threat: Why Monitoring Cloud Service Providers Matters More Than Ever?
Most SaaS and cloud-native applications today do not run in isolation. They rely heavily on third-party infrastructure, APIs, and services - from DNS and storage to authentication and machine learning. This growing interdependence creates a fragile mesh: when one cloud service provider (CSP) experiences downtime, dozens or hundreds of downstream applications feel the impact instantly.
The result? A cascading failure that hits not just a single app but entire stacks of enterprise services. Teams are left scrambling to understand whether the root cause is in their own systems or an upstream provider!
Recent Outages Observed
- Replit + Cloudflare Outage (June 2025): A GCP networking disruption affected both Replits cloud IDE and Cloudflares services, leading to widespread errors and degraded performance. The problem wasn’t inside Replit or Cloudflare, but deep in Googles backbone..
- Slack and Discord Slowdowns (Feb 2024): A minor AWS incident in one region throttled multiple dependent services. Companies lost visibility into the issue for over 30 minutes while waiting for status pages to update
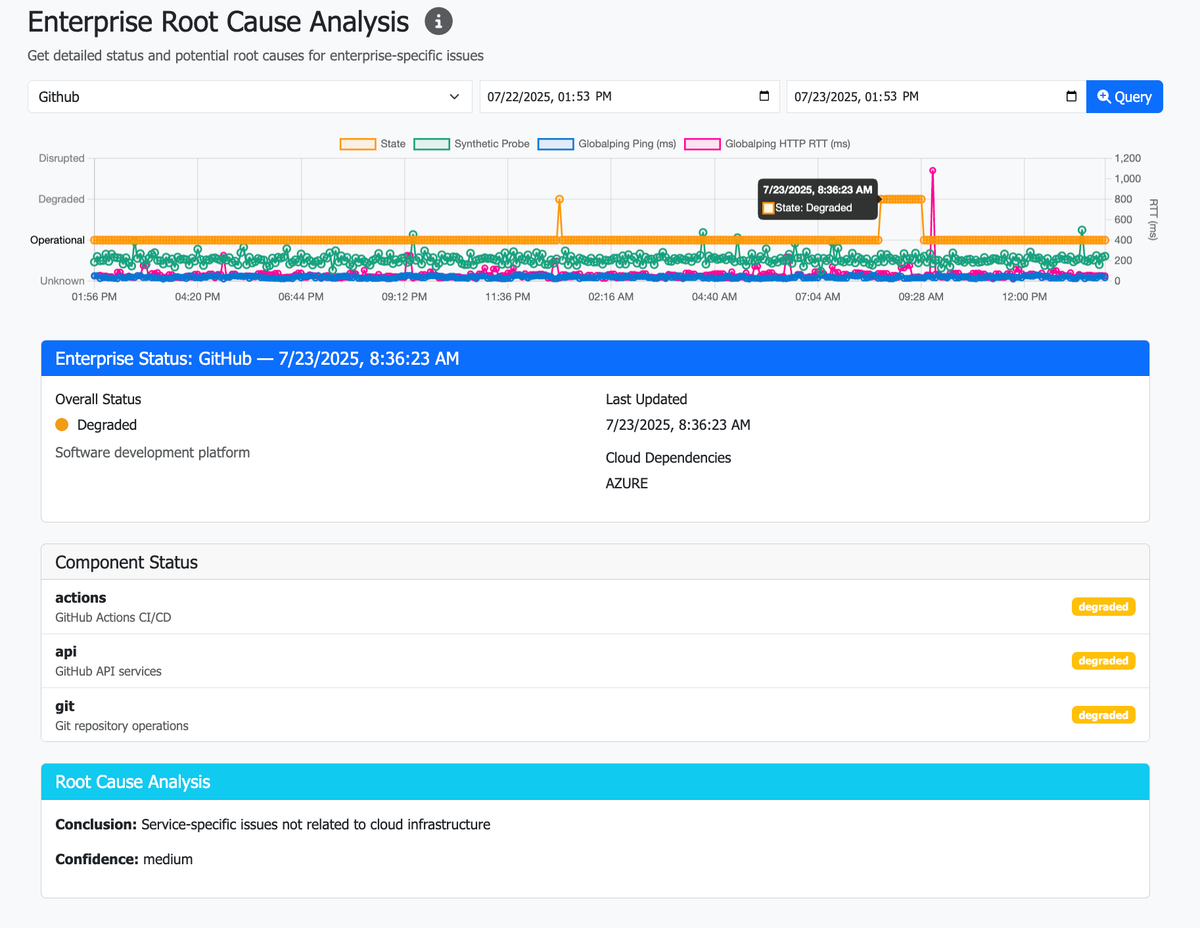
- OpenAI, GitHub, and Notion Incidents (2023): Each of these tools has experienced degraded service not because of internal bugs, but due to failures in services like Cloudflare, Azure, or Fastly
These are not isolated cases. They are patterns.
Why This Matters?
In a cloud-native world, your uptime is only as strong as your weakest external dependency. Enterprises are shifting from monoliths to modular deployments, but with that shift comes a new risk surface. You can no longer ignore what your upstream providers are doing.
Monitoring internal logs and infrastructure is no longer enough. Teams need proactive visibility into the health of the services they depend on - even when those services live outside their control..
Whats Needed Now?
- Real-time monitoring of major CSPs like AWS, GCP, Azure, and Cloudflare
- Early warning signals via probes, latency metrics, and public RSS feeds
- Alerting mechanisms that integrate with team workflows — Slack, email, dashboards
- Correlated impact analysis that maps dependencies (e.g., if GCP is down, these five services may be affected)
- Historical records of previous outages to improve incident response
Essentially Cloud Service Provider outages are no longer rare. They are now part of the operational reality for any team building on modern stacks. Monitoring CSPs isn’t optional anymore - its the first line of defense in protecting your own service availability.
PingPatrol was built with this need in mind